Я специалист по цифровому маркетингу с нулевым опытом программирования.
Я хочу вытащить только первые данные, которые записаны между разделителями (|||)
[VP/NNP] ||| talk here ||| walk here ||| PPDB2.0Score=6.03040 PPDB1.0Score=1.919110 -logp(LHS|e1)=7.19109 -logp(LHS|e2)=0.42834 -logp(e1|LHS)=15.32573 -logp(e1|e2)=0.49145 -logp(e1|e2,LHS)=5.83537 -logp(e2|LHS)=9.49919 -logp(e2|e1)=1.42766 -logp(e2|e1,LHS)=0.00883 AGigaSim=0.91193 Abstract=0 Adjacent=0 CharCountDiff=-1 CharLogCR=-0.03077 ContainsX=0 Equivalence=0.182028 Exclusion=0.008591 GlueRule=0 GoogleNgramSim=0.52732 Identity=0 Independent=0.187394 Lex(e1|e2)=62.90141 Lex(e2|e1)=62.90141 Lexical=1 LogCount=0.69315 MVLSASim=NA Monotonic=1 OtherRelated=0.000021 PhrasePenalty=1 RarityPenalty=0.00005 ReverseEntailment=0.621966 SourceTerminalsButNoTarget=0 SourceWords=6 TargetTerminalsButNoSource=0 TargetWords=6 UnalignedSource=0 UnalignedTarget=0 WordCountDiff=0 WordLenDiff=-0.16667 WordLogCR=0 ||| 0-0 1-1 2-2 3-3 4-4 5-5 ||| ReverseEntailment
Результат:
talk here ||| walk here
Как добиться этого результата с помощью блокнота ++, Microsoft Word или Excel?
2 ответа
Использование Notepad ++
- Ctrl+ЧАС
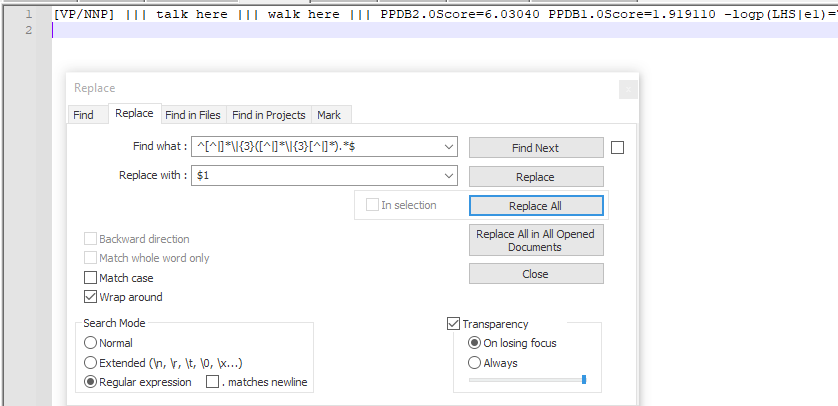
- Найти то, что:
^[^|]*|{3}([^|]*|{3}[^|]*).*$ - Заменить:
$1 - ПРОВЕРИТЬ Обернуть вокруг
- ПРОВЕРИТЬ Регулярное выражение
- НЕ ПРОВЕРИТЬ
. matches newline - Заменить все
Объяснение:
^ # beginning of line
[^|]* # 0 or more any character that is not a pipe
|{3} # 3 pipe character
( # group 1
[^|]* # 0 or more any character that is not a pipe
|{3} # 3 pipe character
[^|]* # 0 or more any character that is not a pipe
) # end group
.* # 0 or more any character
$ # end of line
Замена:
$1 # content of group 1
Скриншот (до):
Скриншот (после):
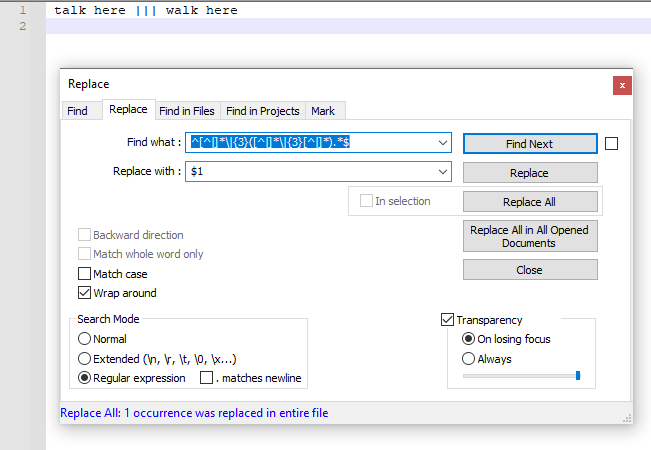
Короткий ответ
Если вы хотите сделать это с помощью Excel, поместите свои данные в ячейку A1и вставьте следующую функцию в любую ячейку:
=MID(A1,
FIND(" ||| ",A1,1)+5,
FIND(" ||| ",A1,FIND(" ||| ",A1,FIND(" ||| ",A1,1)+5)+5)-FIND(" ||| ",A1,1)-5
)
Вы можете обратиться к следующему изображению для пояснения.

Также: Если вы хотите обработать, скажем, 500 данных следующим образом:
- Поместите свои данные на
A1-A500. - Вставьте функцию в
B1. - Копировать
B1и наклеить на ячейкиB2-B500.
По тому пути, Bx будет иметь обработанные данные Ax.
Как я сконструировал функцию
Странная вещь в Excel заключается в том, что он считает индекс от 1 вместо 0.
Имея это в виду, мы имеем:
| Клетка | Содержание | Функция | Сниженная функция |
|---|---|---|---|
A1 | input | — | — |
B1 | delimiter | — | — |
C1 | Индекс символа после первого разделителя | = НАЙТИ (B1; A1,1) +5 | = НАЙТИ («|||»; A1,1) +5 |
D1 | Индекс символа после второго разделителя | = НАЙТИ (B1; A1; C1) +5 | = НАЙТИ («|||»; A1; НАЙТИ («|||»; A1,1) +5) +5 |
E1 | Индекс символа после третьего разделителя | = НАЙТИ (B1; A1; D1) +5 | = НАЙТИ («|||»; A1; НАЙТИ («|||»; A1; НАЙТИ («|||»; A1,1) +5) +5) +5 |
F1 | Символы между первым и третьим разделителями | = MID (A1, C1, E1-C1-5) | = MID (A1, НАЙТИ («|||», A1,1) +5, НАЙТИ («|||», A1, НАЙТИ («|||», A1, НАЙТИ («|||», A1,1) +5) +5) -НАЙТИ («|||», A1,1 ) -5) |
И у нас есть функция!
Однако, если бы я использовал этот файл Excel, я бы не стал сокращать такие функции. Вместо этого я бы сохранил столбцы B-E как скрытые, и просмотрите результаты в F. Это дает нам больше гибкости, а код остается понятным.