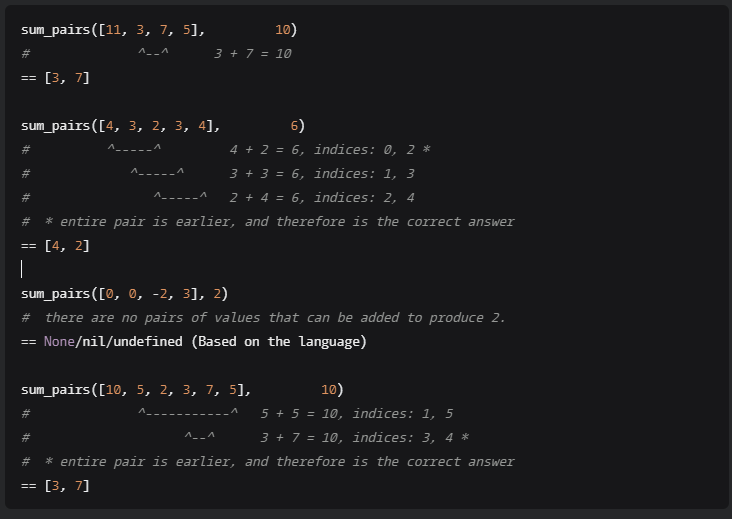
 Мне нужна помощь в оптимизации кода для огромных списков с прибл. 10000000 элементов. Есть ли способ улучшить мой алгоритм или я должен попытаться создать новый, используя совершенно другой подход? Задача: учитывая список целых чисел и одно значение суммы, вернуть первые два значения (пожалуйста, проанализируйте слева) в порядке появления, которые в сумме образуют сумму.
Мне нужна помощь в оптимизации кода для огромных списков с прибл. 10000000 элементов. Есть ли способ улучшить мой алгоритм или я должен попытаться создать новый, используя совершенно другой подход? Задача: учитывая список целых чисел и одно значение суммы, вернуть первые два значения (пожалуйста, проанализируйте слева) в порядке появления, которые в сумме образуют сумму.
def sum_pairs(ints, s):
lst1 = []
for n in ints:
if n in lst1:
return [s-n, n]
lst1.append(s-n)
lst3 = list(range(1,10000000))
sum_pairs(lst3, 20000000)
*Times out :(
#Using set() every time we add new item to the list doesn't help
def sum_pairs(ints, s):
lst1 = []
for n in ints:
lst2 = set(lst1)
if n in lst2:
return[s-n, n]
lst1.append(s-n)
1 ответ
Вы можете использовать набор как lst1 вместо списка. Каждый раз, когда вы проверяете, находится ли n в lst1, это $ O (п) $ временная сложность. Вместо этого использование набора снизит это до $ O (1) $.
Правильный ответ в последнем примере: [3, 7]не [5, 5] потому что 7 появляется в списке целых чисел перед второй «5»
— Лука Брази
Вы правы, я как-то неправильно это понял. Nvm, все, что вам нужно, это использовать набор вместо списка. Тогда должно работать.
— my_first_c_program
Спасибо, я совсем забыл о наборах как об отдельных типах данных, вспомнил только вызов функции, не говоря уже об этом 🙂
— Лука Брази